Deep Q-Network Navigation in PyBullet
Project Overview
This project independently implements a Deep Q-Network (DQN) agent for autonomous navigation in a 2D PyBullet simulation.
The agent learns goal-reaching behavior under uncertainty using value-based reinforcement learning with discrete motion
commands, reward shaping, and exploration decay. The environment extends the simple-car-env-template and
includes visual diagnostics for training evaluation. Developed as part of an advanced robotics module, this project
demonstrates practical skills in learning-based control, simulation engineering, and agent diagnostics.
Demonstration
This section presents a visual walkthrough of the learning process and policy behavior, highlighting both theoretical underpinnings and practical results.

The Markov Decision Process (MDP) framework provides the foundation for value-based reinforcement learning methods like DQN.
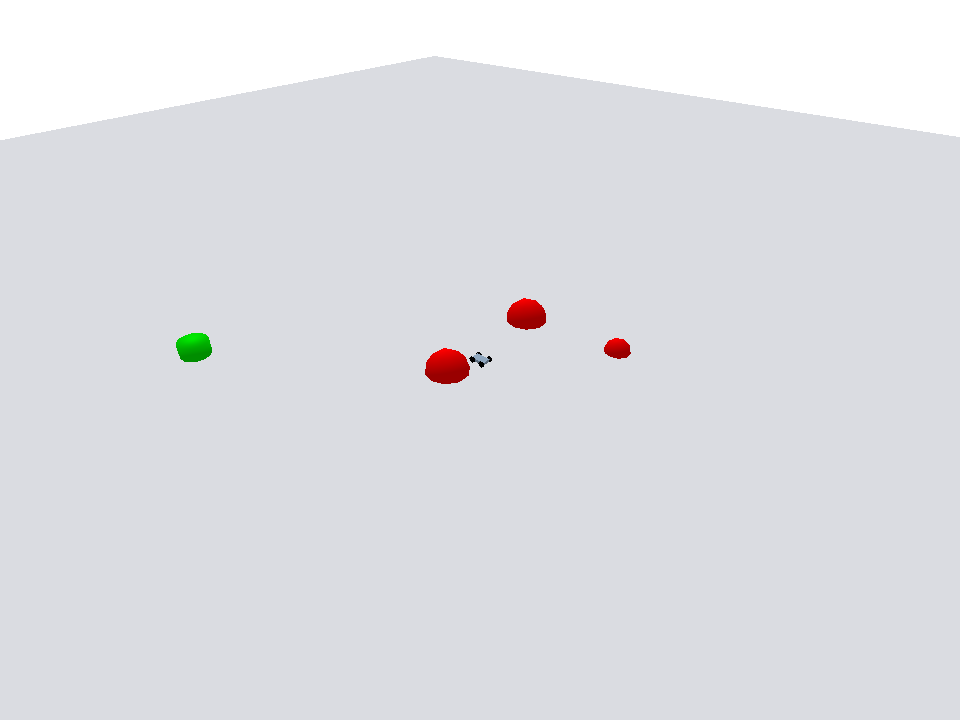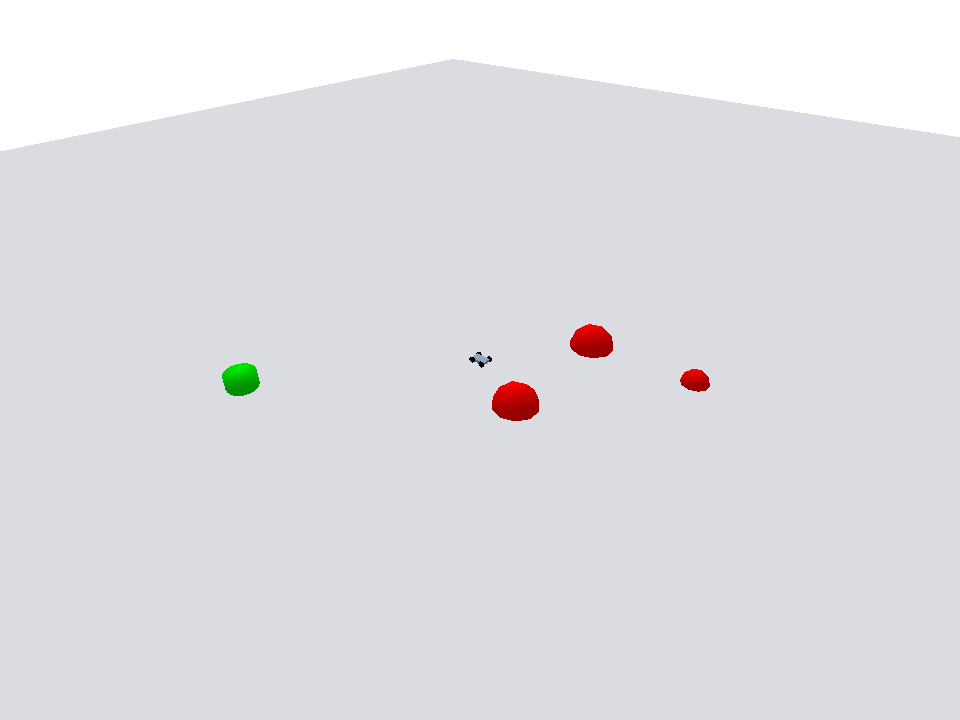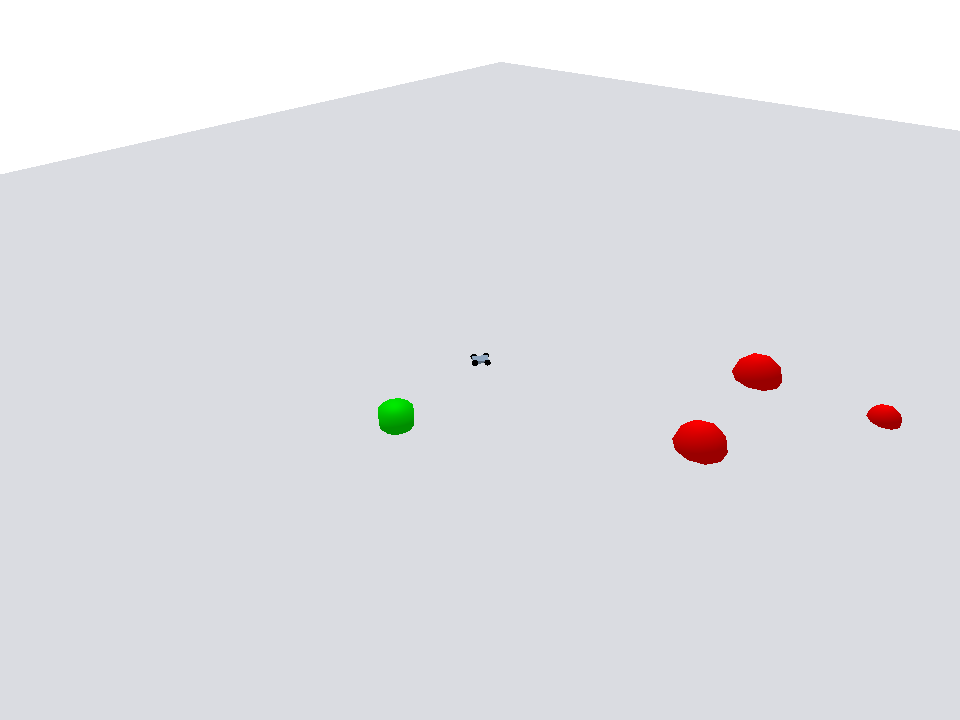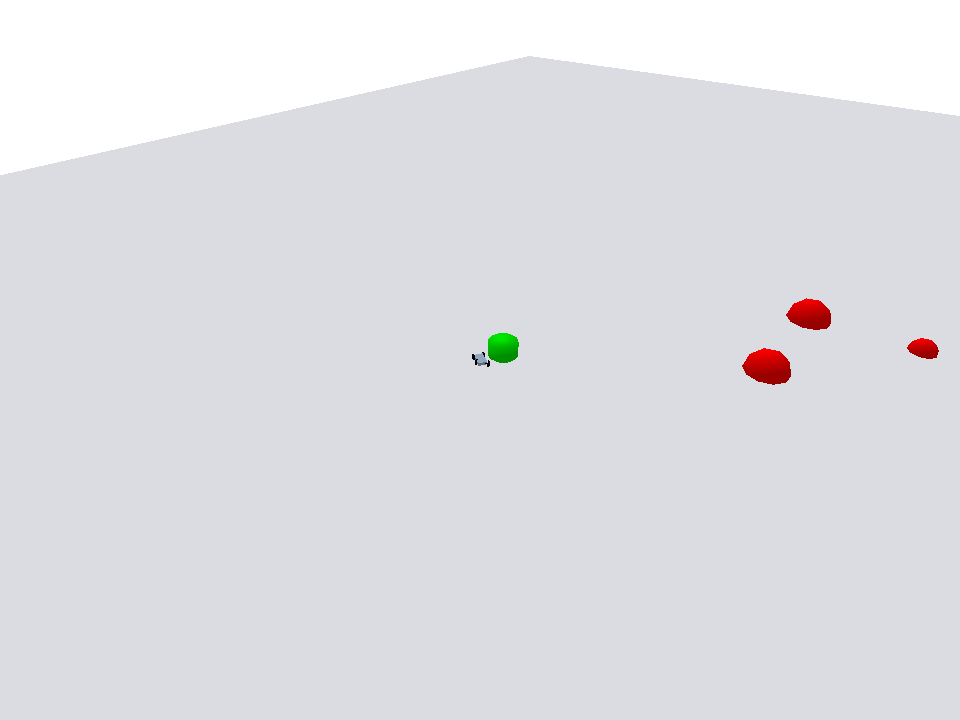
Policy evaluation shows the agent navigating efficiently toward the goal while avoiding dynamic obstacles.
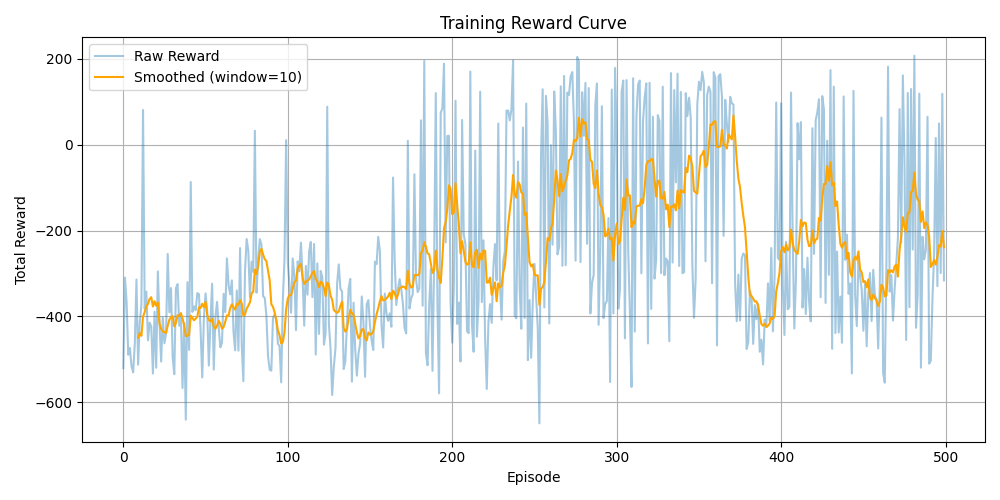
The reward curve demonstrates steady policy improvement over training episodes, validating the agent's learning progression.
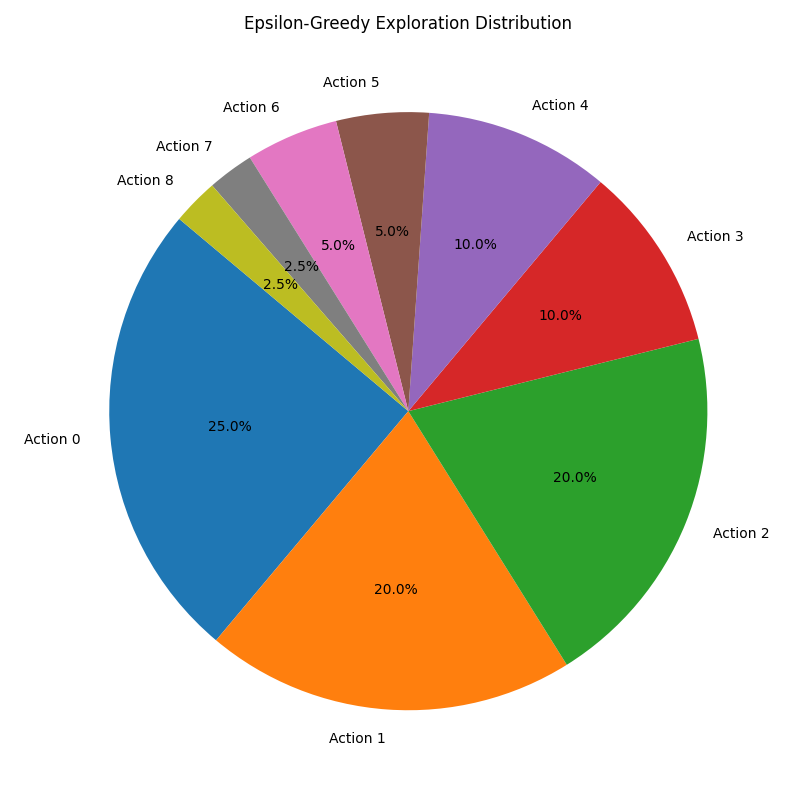
The ε-decay curve reflects the agent’s shift from exploratory to exploitative behavior as training proceeds.
Methods
- ✓ Discrete DQN agent with 9 control actions and a multilayer perceptron (MLP) policy network
- ✓ Simulation environment extended from
simple-car-env-templatewith dynamic obstacle generation - ✓ Reward shaping based on goal proximity, collision penalties, and sparse terminal rewards
- ✓ Epsilon-greedy exploration with exponential decay for efficient policy convergence
- ✓ Evaluation based on success thresholds, cumulative rewards, and behavioral visualization